
Read and watch screencasts up through the Insertion Sort Analysis
Clear and unambiguous definition of what to be solved in terms of:
Descriptions in a problem formulation must be declarative (not procedural). All assumptions concerning input and output must be explicit. The problem formulation provides the requirements for an algorithm.
The numbers are referred to as keys.
Additional information known as satellite data may be associated with each key.
Sorting is hugely important in most applications of computers. We will cover several ways to solve this problem in this course.

Insertion sort takes an incremental strategy of problem solving: pick off one element of the problem at a time and deal with it. Our first example of the text's pseudocode:

Here's a step by step example:
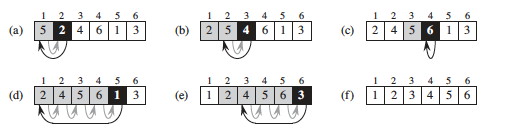
Is the strategy clear? For fun, see the visualization at http://youtu.be/ROalU379l3U
A loop invariant is a formal property that is (claimed to be) true at the start of each iteration. We can use loop invariants to prove the correctness of iteration in programs, by showing three things about the loop invariant:
Notice the similarity to mathematical induction, but here we have a termination condition.
Convinced? Questions? Could you do it with another problem?
If we are going to tally up time (and space) requirements, we need to know what counts as a unit of time (and space). Since computers differ from each other in details, it is helpful to have a common abstract model.
The RAM model is based on the design of typical von Neumann architecture computers that are most widely in use. For example:
We identify the primitive operations that count as "one step" of computation. They may differ in actual time taken, but all can be bounded by the same constant, so we can simplify things greatly by counting them as equal.
These assume bounded size data objects being manipulated, such as integers that can be represented in a constant number of bits (e.g, a 64-bit word), bounded precision floating numbers, or boolean strings that are bounded in size. Arbitrarily large integers, arbitrarily large floating point precision, and arbitrarily long strings can lead to nonconstant growth in computation time.
Here we are stating that the time to execute the machinery of the conditional loop controllers are constant time. However, if the language allows one to call arbitrary methods as part of the boolean expressions involved, the overall execution may not be constant time.
The time to set up a procedure call is constant, but the time to execute the procedure may not be. Count that separately. Similarly, the time to set up an I/O operation is constant, but the time to actually read or write the data may be a function of the size of the data. Treat I/O as constant only if you know that the data size is bounded by a constant, e.g., reading one line from a file with fixed data formats.
Time taken is a function of input size. How do we measure input size?
We now undertake an exhaustive quantitative analysis of insertion sort. We do this analysis in greater detail than would normally be done, to illustrate why this level of detail is not necessary!!!
For each line, what does it cost, and how many times is it executed?
We don't know the actual cost (e.g., in milliseconds) as this varies across software and hardware implementations. A useful strategy when you do not know a quantity is to just give it a name ...

The ci are the unknown but constant costs for each step. The tj are the numbers of times that line 5 is executed for a given j. These quantities depend on the data, so again we just give them names.
Let T(n) be the running time of insertion sort. We can compute T(n) by multiplying each cost by the number of times it is incurred (on each line) and summing across all of the lines of code:
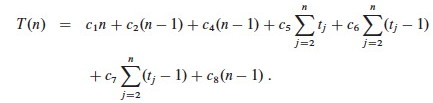
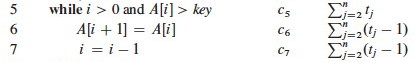
When the array is already sorted, we always find that A[i] ≤ key the first time the while loop is run; so all tj are 1 and tj-1 are 0. Substituting these values into the above:
As shown in the second line, this is the same as an + b for suitable constants a and b. Thus the running time is a linear function of n.
When the array is in reverse sorted order, we always find that A[i] > key in the while loop, and will need to compare key to all of the (growing) list of elements to the left of j. There are j-1 elements to compare to, and one additional test for loop exit. Thus, tj=j.
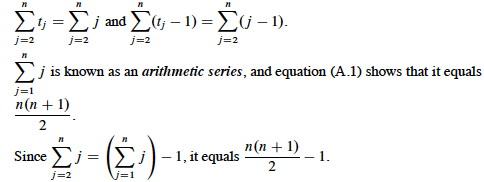
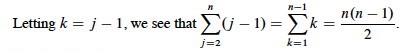
Plugging those values into our equation:
We get the worst case running time, which we simplify to gather constants:

T(n) can be expressed as an2 + bn + c for some a, b, c: T(n) is a quadratic function of n.
So we can draw these conclusions purely from mathematical analysis, with no implementation or testing needed: Insertion sort is very quick (linear) on already sorted data, so it works well when incrementally adding items to an existing list. But the worst case is slow for reverse sorted data.
From the above example we introduce two key ideas and a notation that will be elaborated on later.
Above, both best and worst case scenarios were analyzed. We usually concentrate on the worst-case running times for algorithms, because:
How long does it take on average to successfully find an item in an unsorted list of n
items?
How long does it take in the worst case, when the item is not in the list?
What is the difference between the two?
In the above example, we kept track of unknown but named constant values for the time required to execute each line once. In the end, we argued that these constants don't matter!
This is good news, because it means that all of that excruciating detail is not needed!
Furthermore, only the fastest growing term matters. In an2 + bn + c, the growth of n2 dominates all the other terms (including bn) in its growth.
If we conclude that an algorithm requires an2 + bn + c steps to run, we will dispense with the constants and lower order terms and say that its growth rate (the growth of how long it takes as n grows) is Θ(n2).
If we see bn + c we will write Θ(n).
A simple constant c will be Θ(1), since it grows the same as the constant 1.
When we combine Θ terms, we similarly attend only to the dominant term. For example, suppose an analysis shows that the first part of an algorithm requires Θ(n2) timeand the second part requires Θ(n) time. Since the former term dominates, we need not write Θ(n2 + n): the overall algorithm is Θ(n2).
Formal definitions next class!